We all know very well that the tech giant Google is working hard to synthesize voices that sound more and more like humans. The idea is to make interactions natural with the personal assistant, with Google Home speakers and even with the interpreter.
Google’s AI Learns To Reproduce Human Speech
The tech giant Google is working hard to synthesize voices that sound more and more like humans. The idea is to make interactions natural with the personal assistant, with Google Home speakers and even with the interpreter.
This time the company, of course, the tech giant Google released a new breakthrough in this direction using neural networks. Can you recognize the difference between the human voice and the synthesized voice?
The tech giant Google has created a system called Tacotron 2, for speech synthesis directly from the text. It has several interesting features like correcting your writing: you can type “thisss isrealy awhsome” and then you can simply hear the correct phrase “this is really awesome”.
In addition, the system pronounces words according to meaning. For example, “desert” can be “desert” or “desert” – the neural network detects this and gives the correct emphasis.
It also pauses when it detects commas; changes intonation when asking a question; correctly pronounces more complex terms like “Otolaryngology” or “Talib Kweli”; and is good at tongue-twisters as well.
Most crucial, however, is that the Tacotron 2 draws close to the human voice. In this link, you can find the voice examples, and I bet that you cannot identify which phrase was spoken by a human, and which one was produced by the tech giant Google’s AI (Artificial Intelligence).
The feedback is at the end of the post. I was able to correctly identify the computer generated voices; some differences in speech rhythm allow us to detect this – they are perceptible but very subtle.
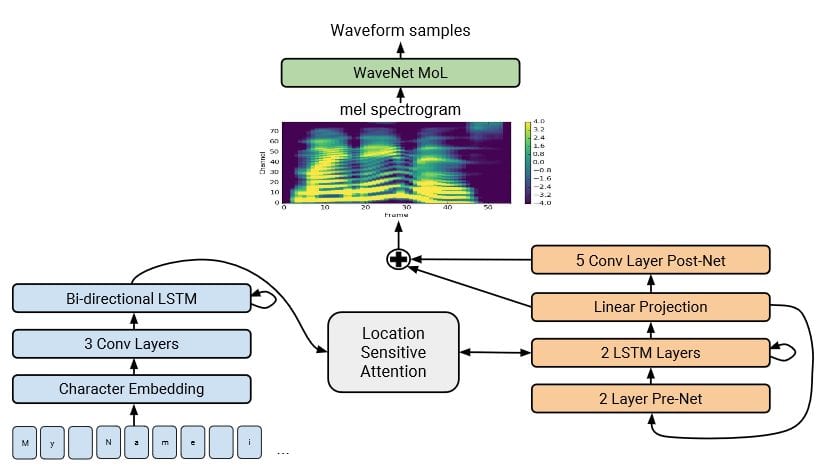
This new technique from the tech giant Google brings together two previous speech generation projects: WaveNet and the original Tacotron.
The WaveNet is a neural network that learns to simulate our voice. It starts with audios recorded by humans, tries to replicate them and improves with each iteration, until creating a synthetic voice close to the real one. It does a simulation using 16,000 samples for every second.
In turn, the original Tacotron served to emulate high-level features, such as intonation and prosody. Together, these two systems “produce a speech that sounds natural and approaches the audio fidelity of real human speech,” write the researchers. The study is available here.
So, what do you think about this? SImply share your views and thoughts in the comment section below.


